This is a guest post by Rachael Lammey, Crossref, Daniella Lowenberg, Make Data Count, Claire Redhead, OASPA
In June 2021, OASPA ran a webinar to showcase the Make Data Count (MDC) initiative, and talk about the importance of data citation for its members. We were really pleased with the engagement on the webinar, lots of discussion and questions, but there’s only so much you can fit into the webinar format.
To follow-up, we contacted a selection of OASPA members who’d attended or signed up for the webinar. We wanted to dig a little deeper into what smaller publishers are thinking about in terms of data, where that sits in their workflows and planning, and the feedback they’re getting from their communities. We know there’s more to do to support publishers in collecting and disseminating data citations, so finding out more about the issues and questions meant that we could then discuss what we can do to provide educational, technical and other support at OASPA, via the Make Data Count initiative and at Crossref.
Claire Redhead (OASPA), Daniella Lowenberg (MDC) and Rachael Lammey (Crossref) were joined by Lauren Collister from the University of Pittsburgh Library System, Armin Günther from the Leibniz Institute for Psychology (ZPID) and Tim Wakeford from Ubiquity Press. We thank them for being so generous with their time and their thoughts on how we could break down barriers to help data be cited consistently across different publications, subject areas and workflows.
Why is data citation important?
- Transparency and reproducibility: Most scientific results that are shared today are just a summary of what researchers did and found. The underlying data are not available, making it difficult to verify and replicate results. If data would always be made available with publications, transparency of research would be greatly improved.
- Reuse: The availability of raw data allows other researchers to reuse the data. Not just for replication purposes, but to answer new research questions.
- Credit: When researchers cite the data they used, this forms the basis for a data credit system. Right now researchers are not really incentivized to share their data, because nobody is looking at data metrics and measuring their impact. Data citation is a first step towards changing that.
What did we find out?
- The willingness is there. Researchers are citing their own and other data and publishers are keen to support and encourage this.
- There are impediments to more widespread adoption of this practice:

We’ve tried to capture these in the screenshot above and group what was discussed as follows:
Green = technical/logistical. Publishers want to make sure they’re putting data citations in the correct place in their Crossref metadata and that these are included, especially if they are also collecting Data Availability Statements (DASs) or if they have citations to data and software in a separate reference list. Conceptually, data citation and a DAS are different things, but that needs to be spelled out carefully in Instructions for Authors and in the submission process.
Orange = outreach. There is lots of guidance out there which, although useful, can make it more difficult to find an authoritative source of information on standards and practices. Discipline-specific guidance and examples would also be helpful. An example we talked about was the Tromsø recommendations for citation of research data in linguistics.
Pink = cultural. In some disciplines, data citation is very common, but if it’s not a standard practice, it can feel a little daunting. In cases where it is an unfamiliar practice and where editorial processes are tried-and-tested already, Editors may not see the immediate gains at the journal level.
Yellow = in practice. Some of these points flow from the others, but assisting authors with good citation practices will help usefully and specifically cite related data in the first place. Publishers reported seeing links to the repository itself, rather than the specific item that’s being cited in that repository. This can be difficult e.g. in Linguistics where a researcher might want to point to the specific usage of a word/phrase in a wider body of work.
What can we do?
We discussed the following measures:
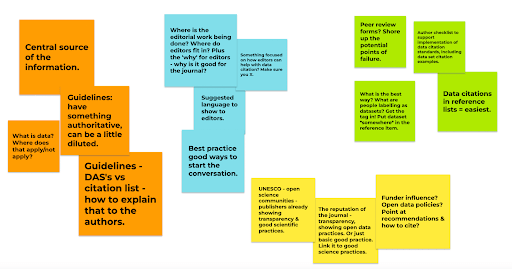
Orange = outreach. Clear guidelines not duplicated across lots of platforms/websites as this can have a diluting effect. We discussed how it’s easy and clear for publishers to link out to the COPE Guidelines, and feel a similar central resource would be helpful. Examples on what a subject area considers data to be, and how it should be cited in combination with data being referenced in a DAS is also key. DASs aren’t actionable in the same way that data citations are (and also ignore data that is being referenced over and above any data the article is built upon). In our outreach, we need to communicate why citations should be prioritized over DASs.
Blue = editor-specific outreach. Resources for editors on the Make Data Count site: resources for publishers and repositories exist but information on how editors can help with data citation, and why it’s valuable for their journal and their authors, would offer a support. . Publishers could share these with their editors to start the conversation and encourage best practice. The interface with Crossref comes further down the line, most often by the publishers, therefore helping editors who intervene early in the process and set the practices for their journal is key.
Green = technical/logistical. Shoring up the submission/peer review workflow around data citation to stop references to data being lost along the way. Crossref support of simple/easy ways for publishers to identify these (e.g. using the term ‘dataset’ in a reference.)
Yellow = the bigger picture and other parties. Open access publishing (and publishing in general) faces ongoing scrutiny regarding quality. Many publications are showing increased transparency in their practices and workflows to demonstrate the work that they do, including sharing and citing data, coupled with external initiatives like the TOP Factor. This is supported by the November 2021 adoption of the UNESCO Recommendation on Open Science. Funders also play a role in adopting open data policies that speak to the importance of citing any underlying or related data.
What will we do?
- Provide a clear message on why data citation is the optimal practice (as opposed to availability statements)
- Optimize messaging and guidance from MDC and Crossref
- Create extended resources for editors, through the publishing lifecycle
- Clarify guidance from Crossref on how to tag data citations in reference lists
- Share these resources with OASPA members and continue support on the data citation and data metrics journey:

And, like any journey, it’s best not to do it alone. If you have additional suggestions as to how we can support you and your communities, please get in touch!
For more information about Make Data Count, visit: https://makedatacount.org/
For Crossref’s guide to data citation for publishers, visit: https://www.crossref.org/community/data-citation/